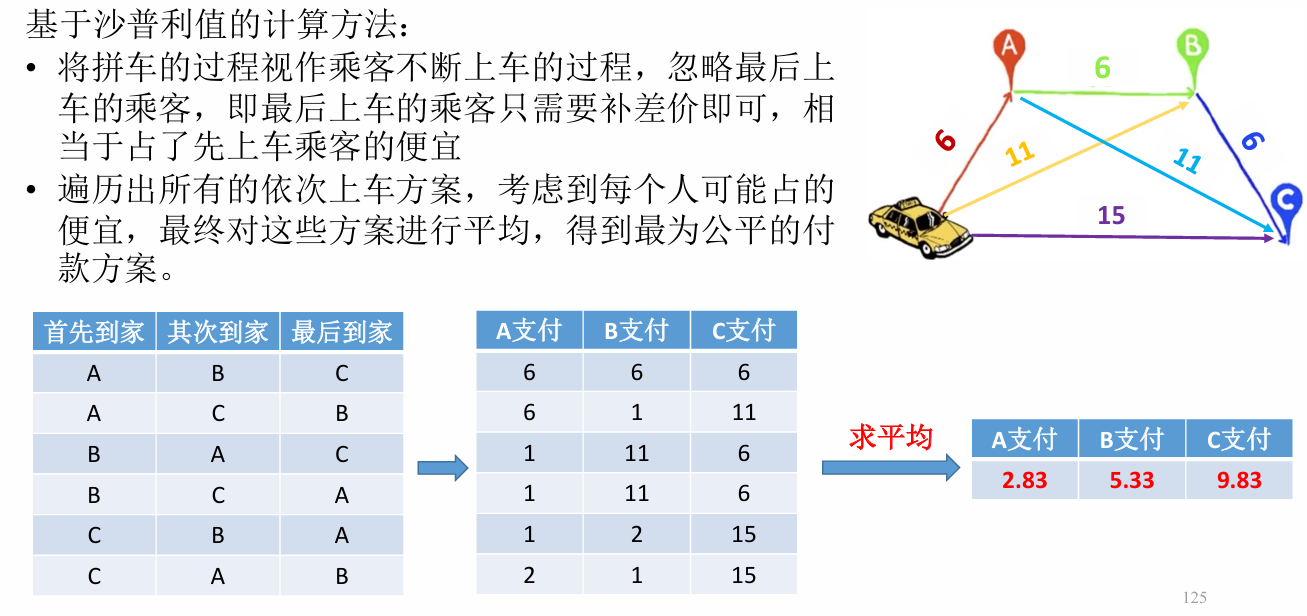
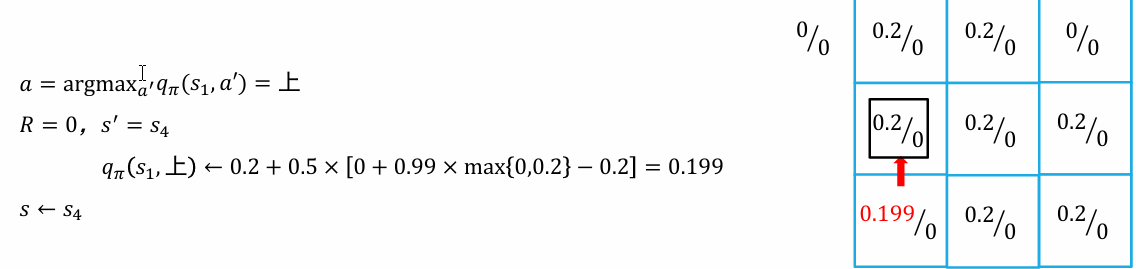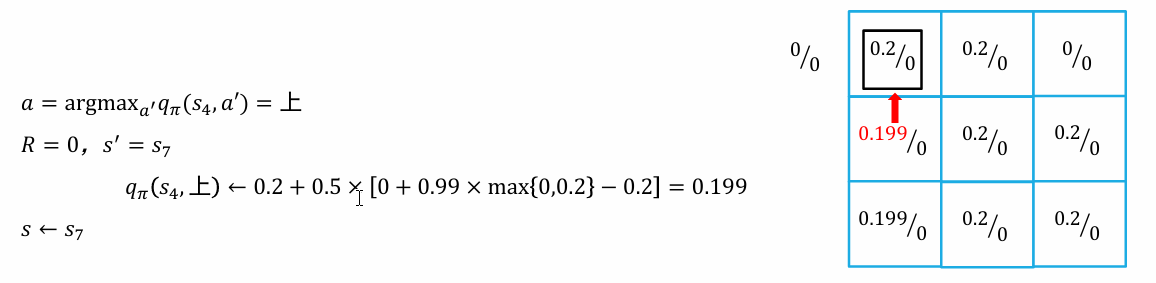01 强化学习定义:马尔科夫决策过程
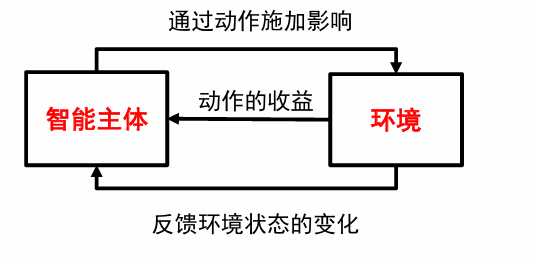
在智能主体与环境的交互中,学习能最大化收益的行动模式:
离散马尔可夫过程 Discrete Markov Process
基本概念
随机过程:是一列随时间变化的随机变量;
- 当时间是离散量时,一个随机过程可以表示为 , 其中每个 都是一个随机变量,这被称为离散随机过程
马尔可夫链(Markov Chain):满足马尔可夫性(Markov Property)的离散随机过程,也被称为离散马尔科夫过程
- 𝒕+𝟏时刻状态仅与𝒕时刻状态相关
- 二阶:𝒕 +𝟏时刻状态与𝒕和𝒕−𝟏时刻状态相关
马尔可夫奖励过程(Markov Reward Process):引入奖励
- 奖励函数 , 其中 描述了从第 步状态转移到第 步状态所获得奖励
- 在一个序列决策过程中,不同状态之间的转移产生了一系列的奖励 , 其中 为 的简便记法
- 为了比较不同的奖励序列,定义反馈 (return), 用来反映累加奖励:其中衰退系数 (decay factor)
马尔可夫决策过程(Markov Decision Process):引入动作
- 定义智能主体能够采取的动作集合为
可以是无限的
- 由于不同的动作对环境造成的影响不同,因此状态转移概率定义为 ,其中 为第 步采取的动作
可以是随机概率性的转移
- 奖励可能受动作的影响,因此修改奖励函数为
例子

使用离散马尔可夫决策过程描述机器人移动问题:
- 随机变量序列 : 表示机器人第 步所在位置(即状态),每个随机变量 的取值范围为
- 动作集合:
- 状态转移概率 : 满足马尔可夫性,其中 。状态转移
- 奖励函数:
- 衰退系数:
综合以上信息,可通过 来刻画马尔科夫决策过程
- 马尔可夫决策过程 是刻画强化学习中环境的标准形式
- 马尔可夫决策过程可用如下序列来表示:
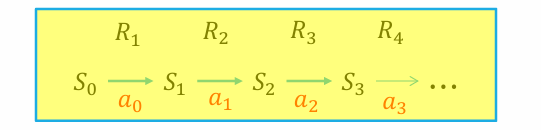
- 马尔科夫过程中产生的状态序列称为轨迹 (trajectory), 可如下表示
- 轨迹长度可以是无限的,也可以有终止状态 。有终止状态的问题叫做分段的 (episodic), 否则叫做持续的 (continuing)
- 分段问题中,一个从初始状态到终止状态的完整轨迹称为一个片段 (episode)
策略学习
智能主体如何与环境交互而完成任务?需要进行策略学习
- 已知的:S A R
- 不一定已知的:Pr
- 观察到的:
策略函数:
- 策略函数 , 其中 的值表示在状态 s 下采取动作 的概率
- 策略函数的输出可以是确定的,即给定 s 情况下,只有一个动作 使得概率 s, 取值为 1。对于确定的策略,记为
为了对策略函数𝜋进行评估,定义
- 价值函数 (Value Function)
, 其中
即在第 步状态为 s 时,按照策略 行动后在未来所获得反馈值的期望
- 动作-价值函数 (Action-Value Function)
, 其中
表示在第 步状态为 s 时,按照策略 采取动作 后,在未来所获得反馈值的期望
这样,策略学习转换为如下优化问题:寻找一个最优策略 , 对任意 使得 值最大
价值函数与动作-价值函数的关系——贝尔曼方程(Bellman Equation)
02 策略优化与策略评估
强化学习求解:在策略优化和策略评估的交替迭代中优化参数

强化学习的求解方法:
- 基于价值 (Value-based) 的方法
- 基于策略 (Policy-based) 的方法
- 对策略函数直接进行建模和估计, 优化策略函数使反馈最大化
- 基于模型 (Model-based) 的方法
- 对环境的运作机制建模,然后进行规划 (planning) 等
基于价值(Value-based)的方法
策略优化
给定当前策略 、价值函数 和行动-价值函数 时,可如下构造新的策略 , 要满足如下条件:
策略评估
通过迭代计算贝尔曼方程进行策略评估
- 动态规划
- 蒙特卡洛采样
- 时序差分(Temporal Difference)
动态规划
- 初始化 函数
- 循环
- 直到 收敛
蒙特卡洛采样
- 选择不同的起始状态,按照当前策略 采样若干轨迹,记它们的集合为D
- 枚举
- 计算 中 s 每次出现时对应的反馈
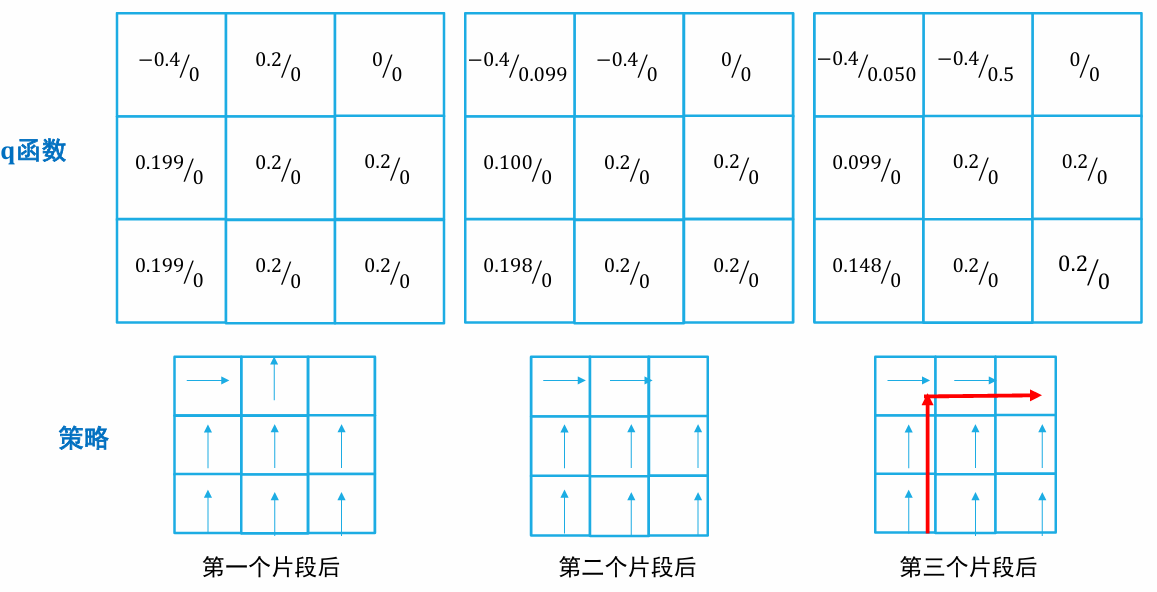
时序差分
- 初始化 函数
- 循环
- 初始化 s 为初始状态
- 循环
- 执行动作 , 观察奖励 和下一个状态
- 更新
- 直到 s 是终止状态
- 直到 收敛
基于策略(Policy-based)的方法
通过直接参数化策略函数的方法求解强化学习问题;算法需要求参数化的策略函数的梯度,因此这些方法称为策略梯度法
- 策略函数的参数化可以表示为 ,其中θ为一组参数,函数取值表示在状态 s 下选择动作 a 的概率
- 和 Q 学习的ϵ贪心策略相比,选择一个动作的概率是随着参数的改变而光滑变化的,对算法收敛有更好的保证
假设强化学习问题的初始状态为 ,不难定义算法希望达到的最大化目标为:
策略梯度定理
如果能够计算或估计策略函数的梯度,智能体就能直接对策略函数进行优化:
- 称为策略 的策略分布 (这里假设折扣系数 )
- 在持续问题中, 为算法在策略 安排下从 出发经过无限多步后位于状态 的概率
- 在分段问题中, 为归一化后的算法从 出发访问 s 次数的期望。
- 当 时,则需要给每个状态的 值加上一个权重
- 为了简化说明,下文在进行公式推导时始终假设
基于蒙特卡洛采样的策略梯度法:REINFORCE
- 算法只需根据策略来采样一个状态 s、一个动作 a 和将来的轨迹,就能构造公式中求取期望所对应的一个样本
- 利用采样得到的轨迹片段来估计梯度,并使用梯度上升法来优化策略
基于时序差分的策略梯度法:Actor-Critic 算法
- 使用下一时刻状态的价值函数来估计当前状态的价值函数,而不是使用整个片段的反馈值
- 和 DQN 一致,计算 q 值时使用另一套参数 w 进行计算
03 Q-Learning
- 初始化 函数
- 循环
- 初始化 s 为初始状态
- 循环
- 执行动作 , 观察奖励 和下一个状态
- 更新
- 直到 s 是终止状态直到
- 收敛
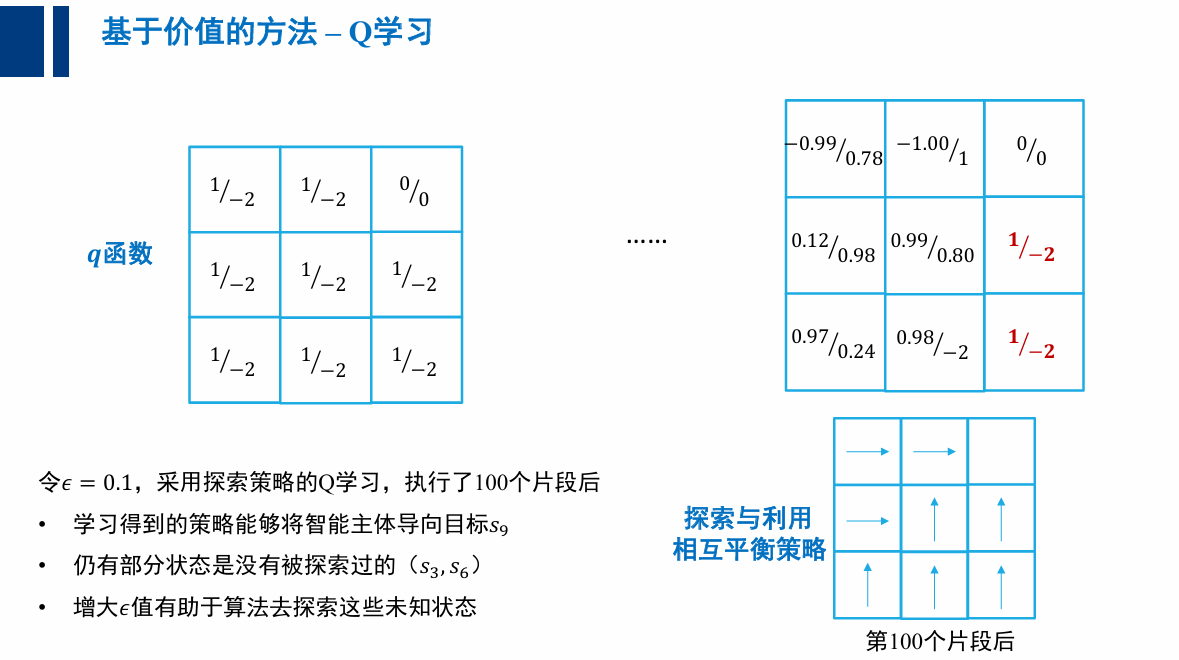
探索(exploration)与利用(exploitation)的平衡
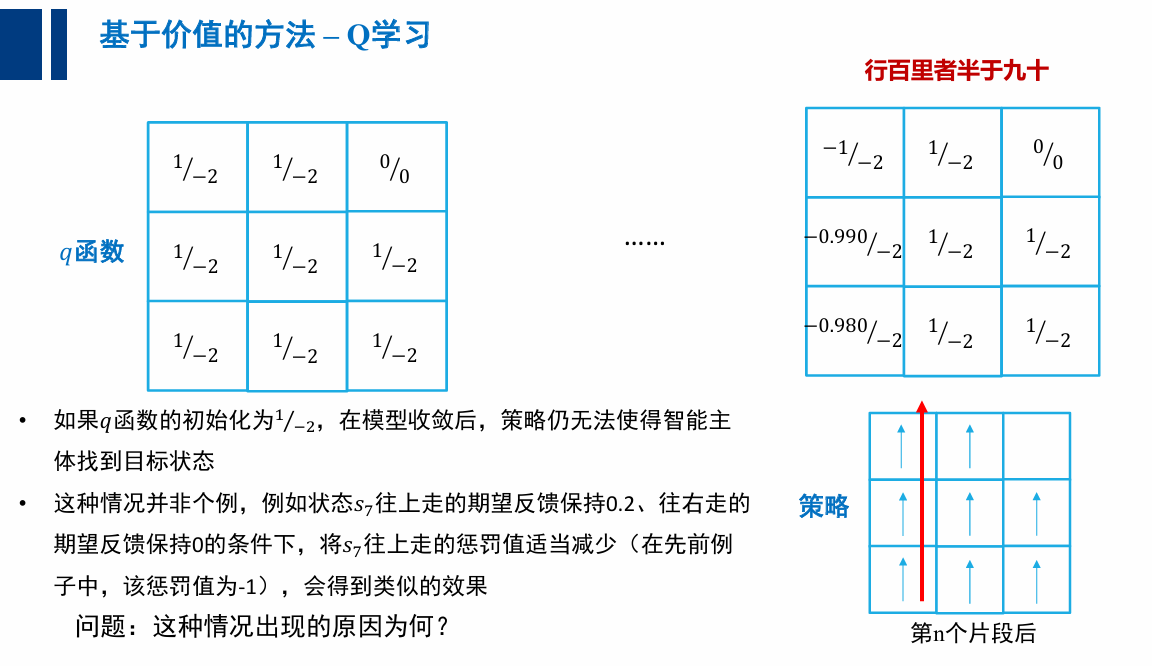
为何 Q 学习收敛到非最优策略?
- 算法中只有利用没有探索
- (特定的 q 初始 q 函数,会让策略无法改变其轨迹)
大体上利用,偶尔探索👇
贪心( -greedy)策略:
加上
贪心(
-greedy)策略后的 Q-Learning
- 初始化函数
- 循环
- 初始化 s 为初始状态
- 循环
- 执行动作, 观察奖励和下一个状态
- 更新
- 直到 s 是终止状态直到
- 收敛
04 深度强化学习
深度 Q 学习
- 状态数量太多时,有些状态可能始终无法采样到
- 状态数量无限时,不可能用一张表 (数组) 来记录𝑞函数的值
👉 将𝑞函数参数化(parametrize),用一个非线性回归模型来拟合𝑞函数,例如 (深度) 神经网络

伪代码:深度 Q 学习
- 初始化函数的参数
- 循环
- 初始化 s 为初始状态
- 循环
- 采样
- 执行动作, 观察奖励和下一个状态 s'
- 损失函数 L
- 根据梯度更新参数
- 直到 s 是终止状态
- 指导 收敛
两个不稳定因素:
- 相邻的样本来自同一条轨迹,样本之间相关性太强,集中优化相关性强的样本可能导致神经网络在其他样本上效果下降
- 在损失函数中,𝑞函数的值既用来估计目标值,又用来计算当前值。现在这两处的𝑞函数通过𝜃有所关联,可能导致优化时不稳定
经验重现 Experience Replay
- 将过去的经验存储下来,每次将新的样本加入到存储中去,并从存储中采样一批样本进行优化
- 解决了样本相关性强的问题
- 重用经验,提高了信息利用的效率
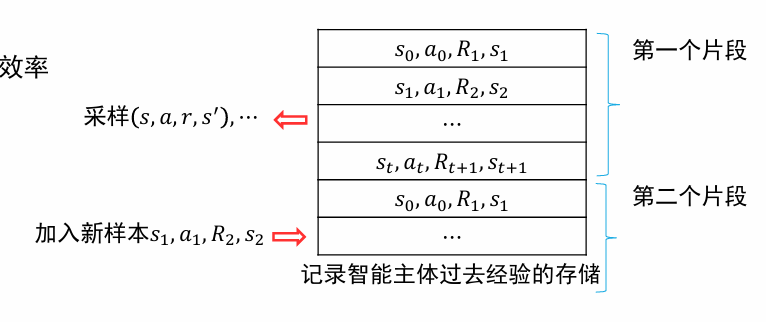
目标网络 Target Network
$$\frac12[R+\gamma\max_{a^{\prime}}\boxed{q_\pi (s^{\prime}, a^{\prime};\theta^{-})}-q_\pi (s, a;\theta)]^2$$
- 损失函数的两个𝑞函数使用不同的参数计算
- 用于计算估计值的使用参数计算,这个网络叫做目标网络
- 用于计算当前值的使用参数计算
- 保持的值相对稳定,例如每更新多次后才同步两者的值
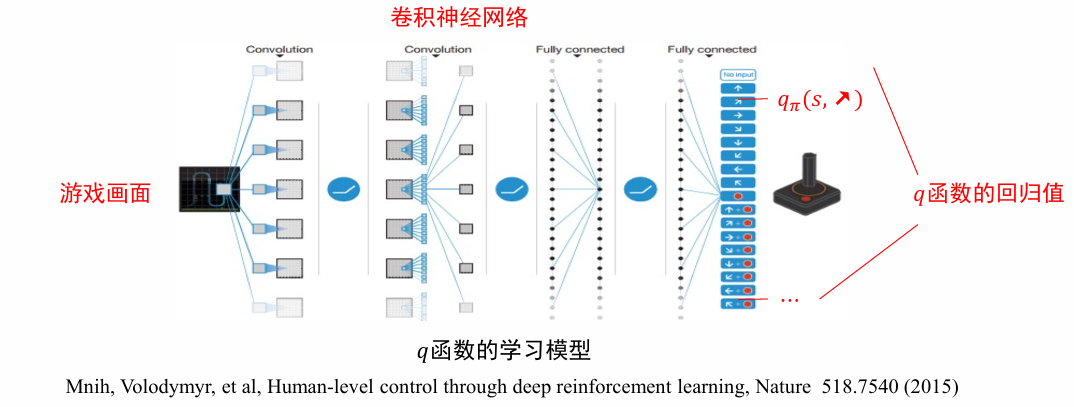
Tips of Q-Learning
05 多智能体强化学习
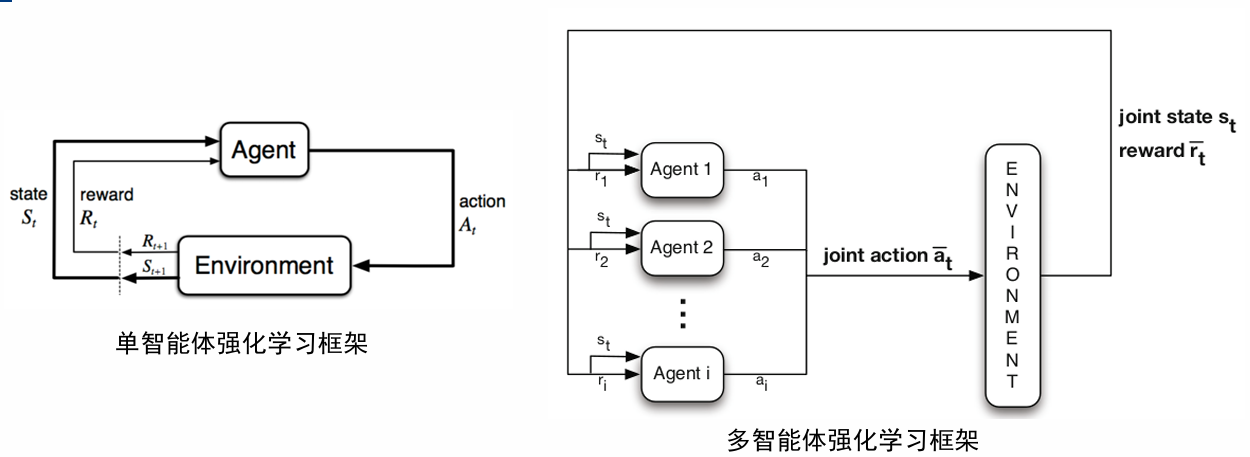
两个问题:
- 多智能体信用分配问题 (Credit Assignment)
- 当只存在 Global reward 时,如何为每个智能体分配 Reward or Value function
- 多智能体通信学习问题 (Communication Learning)